LINE to Present Research at International Conferences in the Field of Data
2022.06.28 Technology
● Research papers selected for presentation at SIGMOD 2022 and VLDB 2022
● Researchers developed new database and machine learning-related technology for privacy protection
TOKYO – June 15, 2022 –LINE Corporation is pleased to announce that two of its research papers on privacy protection have been selected for presentation at world-renowned international conferences, SIGMOD 2022 and VLDB 2022.
The ACM Special Interest Group on Management of Data (SIGMOD), hosted by the Association for Computing Machinery, and the 48th International Conference on Very Large Databases (VLDB), hosted by Very Large Data Base Endowment Inc., are two of the world's top conferences in the field of databases and data engineering. It is the first time that LINE's research papers were accepted at these conferences. The papers were written based on a joint research by Professor Masatoshi Yoshikawa and Program-Specific Associate Professor Yang Cao of the Graduate School of Informatics at Kyoto University. One has been presented at SIGMOD 2022 (held on June 12–17) while the other will be presented at VLDB 2022 in September this year.
LINE's focus on privacy-protecting technology in R&D
While LINE has been focusing on personalization using user data, it also places a high priority on privacy when handling data. The technology and way of thinking about privacy protection have rapidly advanced with relevant international regulations being further established in recent years. As a platformer, one of the company's important responsibilities is to pursue and introduce a privacy model that is appropriate to the times. LINE will test and implement advanced privacy-preserving machine learning techniques such as federated learning, differential privacy, and secure computing to achieve both privacy protection and deep personalization for our diverse users. LINE has already produced great results in privacy protection research. Recently, its research papers on differential privacy (DP) were selected for presentation at top international conferences including ICDE 2021 and ICLR 2022. DP is a mathematically rigorous privacy standard for collecting and utilizing user data. It is used for generating outputs in a way that an individual cannot be distinguished from any other person in the data by adding randomness to it. Currently, LINE is conducting R&D on the practical application of privacy-preserving data utilization with DP.
A world-first approach to amplifying DP via decentralized protocols
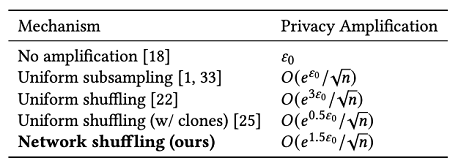
The research presented at SIGMOD proposes a novel method to protect privacy when a server collects data from clients. It is called network shuffling, a new privacy amplification*1 technique that amplifies the strength of DP guaranteed to clients as they securely exchange data with each other. Shuffling is a process in privacy amplification that keeps the identity of the data senders anonymous. In existing privacy amplification techniques, the process had to rely on using a centralized and trusted third party. However, network shuffling is a decentralized shuffling method, meaning that it does not require a centralized third-party server as it involves various clients secretly exchanging data with each other using a social network that utilizes end-to-end (E2E) encryption. After formalizing this exchange of data among clients as a random walk*2 on graphs, it has been confirmed that network shuffling produces similar privacy amplification effects as that of existing shuffling mechanisms.
Overview of network shuffling, a decentralized privacy amplification technique
(The data senders' identity is anonymized by T rounds of secure data exchanges, or random walks)

Privacy amplification effect
(Network shuffling is proven to have similar privacy amplification effects as that of the existing uniform shuffling method)
Privacy amplification per graph data
(Privacy amplification becomes more significant when the graph is larger in scale)

Realization of highly space efficient database queries that preserve both data utility and privacy
The research proposes a new method to protect database query processing with DP called HDPView. It involves constructing a subset of data (view) from very large databases (VLDB) that can respond to an arbitrary query with a small amount of noise. Existing methods to achieve query processing with DP include adding noise at each query response, as well as constructing a subset of data with noise added in advance. The former have limits on the number of queries that can be issued, etc. while the latter can only be optimized for a given set of queries. The problem with both methods is that they are not suitable for data exploration. Therefore, to overcome this problem, HDPView was designed to be query independent, highly space efficient, applicable to high-dimensional data, and able to estimate errors. Experiments have confirmed that it greatly outperforms existing methods mainly in terms of analysis errors and view size.
Issue solved with HDPView
P-view (a database view) has been constructed to answer arbitrary queries with only a small amount of noise

Comparing error of queries and view size
(The table below shows that HDPView outperforms existing methods)

*1 An anonymization process to increase the strength of DP guaranteed to clients. It involves shuffling, a mechanism that anonymizes the sender of the data and helps achieve the desired amplification effect.
*2 A random movement from one point to another. The research looks at the movement between nodes on a graph, where the next node to move on to is randomly decided from among the connected nodes.
Accepted papers
●Network Shuffling: Privacy Amplification via Random Walks
Seng Pei Liew, Tsubasa Takahashi, Shun Takagi, Fumiyuki Kato, Yang Cao, Masatoshi Yoshikawa
(SIGMOD 2022)
●HDPView: Differentially Private Materialized View for Exploring High Dimensional Relational Data
Fumiyuki Kato, Tsubasa Takahashi, Shun Takagi, Yang Cao, Seng Pei Liew, and Masatoshi Yoshikawa
(VLDB 2022)
LINE's focus on basic research
LINE conducts basic research into various technologies that support appropriate operation of data such as privacy protection and the creation of AI-driven services and features. When it comes to basic research, LINE has placed machine learning at the center while focusing on research areas such as speech, language, and image processing. Recent recognition of LINE's research includes the following:
- ICASSP 2022, the international conference in the field of speech, acoustics and signal processing, accepted three of LINE's research papers*3
- INTERSPEECH 2021, the international conference on speech processing, accepted six of LINE's research papers*4
- ICCV 2021, the international conference on computer vision, accepted two of LINE's research papers*5
*3 Press release published on February 17, 2022 : https://linecorp.com/en/pr/news/en/2022/4186
*4 Press release published on August 30, 2021 : https://linecorp.com/ja/pr/news/en/2021/3919
*5 Press release published on July 28, 2021 : https://linecorp.com/ja/pr/news/ja/2021/3843 (Japanese only)
Going forward, LINE will continue to actively work on developing businesses and boosting service quality to further expand its growth and vast potential as a communication platform.