Eight Research Papers Selected for Largest International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2023
2023.05.02 Technology
● Reviewers highly rated research on speech recognition and synthesis
● Number of selected papers that were lead-authored by LINE doubled from last year
TOKYO – April 14, 2023 – LINE Corporation is pleased to announce that eight of its research papers have been selected for presentation at the renowned International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2023 (Rhodes, Greece). Hosted by the IEEE Signal Processing Society—the longest serving society of the Institute of Electrical and Electronics Engineers—the conference will be held for the 48th time this year from June 4 to 10.
Of the eight papers, six were lead-authored by LINE—a two-fold increase from last year’s three—while the other two were co-authored with other research groups. All of the papers will be presented at the upcoming conference.
Papers recognized for their proposed methods on generating natural-sounding speech using emotional speech synthesis, speech separation, and more
Paper [4] proposes an end-to-end emotional text-to-speech (TTS) system that uses the pitch information of human speech. Although the conventional end-to-end approach—which converts text sequence to speech with a single model—generally synthesizes high-quality speech, it typically suffers from quality degradation when it is applied to emotional speech synthesis where the target speech is very expressive. The proposed method explicitly modeled the pitch information of speech, which is essential in emotional speech synthesis. This pitch modeling can represent the pitch information of synthesized speech more accurately, enabling the stable generation of natural-sounding speech samples even for speakers with very high or low pitch value that were difficult to model in conventional methods (Fig. 1).
Paper [5] tackles the problem of recovering individual speech segments out of a mixture of overlapping speakers. It uses diffusion models as a solution, which has recently been popularized for image generation (Fig. 2). In conventional deep learning-based speech separation, the network is trained to maximize an objective metric of speech quality, but unlike the sensitive human ears, objective metrics often fail to account for the subtle distortion of speech. The proposed method produces separated speech that is more natural sounding and pleasant as it relies on a generative model. More precisely, the diffusion model-based speech separation solution improves upon conventional methods in terms of the non-intrusive speech quality metric DNSMOS.
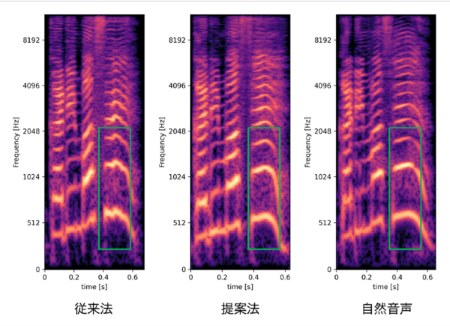
Fig. 1: Mel-spectograms of the synthesized and natural speech

Fig. 2: Illustration of the diffusion-mixing process.
Accepted papers
1. R. Yamamoto et al., "NNSVS: NEURAL NETWORK BASED SINGING VOICE SYNTHESIS TOOLKIT"
2. R. Yoneyama et al., "Non-parallel High-Quality Audio Super Resolution with Domain Adaptation and Resampling CycleGANs"
3. M. Kawamura et al., "LIGHTWEIGHT AND HIGH-FIDELITY END-TO-END TEXT-TO-SPEECH WITH MULTI-BAND GENERATION AND INVERSE SHORT-TIME FOURIER TRANSFORM"
4. Y. Shirahata et al., "Period VITS: Variational inference with explicit pitch modeling for End-to-End emotional speech synthesis"
5. R. Scheibler et al., "DIFFUSION-BASED GENERATIVE SPEECH SOURCE SEPARATION"
6. Y. Fujita et al., "Neural Diarization with Non-autoregressive Intermediate Attractors"
7. T. Kawamura et al., "Effectiveness of Inter- and Intra-Subarray Spatial Features for Acoustic Scene Classification"
8. H. Zhao, et al., "Conversation-oriented ASR with multi-look-ahead CBS architecture"
Note: Papers 1-6 were lead-authored by LINE researchers while papers 7 and 8 were co-authored with Tokyo Metropolitan University and Waseda University respectively.
While developing new AI-driven services, LINE has also been focusing its efforts on conducting AI research and development. In particular, the company has presented influential research on speech recognition and synthesis at top conferences in the field of speech processing. Some examples of cutting-edge technologies developed by LINE researchers include Parallel WaveGAN*1 (capable of quickly producing high quality speech), and self-conditioned CTC,*2 which has been demonstrated as being the most accurate among non-autoregressive automatic speech recognition*3 (a type of high-speed method for speech recognition) models. In the field of environmental audio analysis, LINE researchers also won first place at the international DCASE2020 competition.
Going forward, LINE will continue to enhance its services as well as create new features and services by proactively advancing basic research on AI.